Process
프로세스란, 프로그램이 메모리에 올라가 실행되는 단위를 뜻합니다. 조금 더 와닿게 이야기하자면, 윈도우즈의 경우 작업 관리자를 켜면 프로세스 목록을 볼 수 있죠. 그것들입니다. 아주 쉽게 이야기 하면 ‘메모리에 올라간 프로그램’이라고 할 수 있습니다. ‘프로그램’은 보통 보조기억장치(HDD, SSD)에 있는 바이너리 코드를 뜻한다고 합니다.(Thank you Wikipedia!)
조금 더 이야기하자면, 프로그램 하나를 실행 시켜도 여러개의 프로세스가 뜰 수 있습니다. 아주 간단한 예로 크롬을 봐도 되겠죠. 크롬을 실행해서 탭을 여러 개 띄워 두면 크롬 뭐시기라고 적혀 있는 프로세스가 여러 개 떠 있는 걸 볼 수 있습니다.
Process Memory Layout
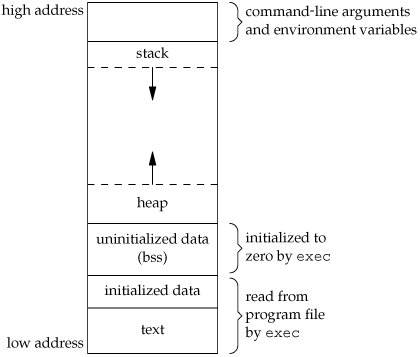 프로세스의 메모리 레이아웃은 위 그림과 같습니다.
프로세스의 메모리 레이아웃은 위 그림과 같습니다.
제일 작은 메모리 주소에 있는(0x00000000 쪽) 부분은 text segment, code segment 라고도 합니다. 즉, 코드를 저장하는 부분입니다.
그 위로 있는 부분은 initialized Data Segment 로 초기화해서 변하지 않을 변수를 저장하는 구역입니다. 즉, 변하지 않을 변수들만 저장하는 부분이죠.
그 위로 있는 부분은 BSS Segment, uninitialized data segment 라고도 합니다. 적혀있는 대로 초기화되지 않은 전역 변수나 정적(static)변수를 저장합니다.
static int i;이런 것들 말입니다.
그 위로 있는 부분은 heap 으로 동적 메모리 할당시 쓰입니다. 많이 써 보셨죠? malloc, new 등등.. 그 함수로 할당되는 메모리들은 보통 힙에 저장됩니다. 이 힙 영역은 멀티 스레딩에서 공유 되는 영역입니다.
그 위로 마지막에 있는 부분은 stack 입니다. 아시다시피 스택은 마지막에 넣은 것들이 먼저 빠지죠. 그걸 이용해서 함수 포인터나 지역 변수를 저장합니다. 즉, 맨 마지막에 넣은(= 제일 deep한) 지역 변수 부터 없어지는거죠. 함수 호출 스택도 똑같구요.
fork()
프로세스를 만드는 함수입니다. UNIX계열(Linux계열 포함)에서 볼 수 있습니다. fork()의 함수 사용 예는 다음과 같습니다.
int main(char[] args){
pid_t pid; /* int, pid_t, whatever. */
pid = fork();
if(pid == -1){ /* Fork FAIL */
perror("fork failed!");
}
else if(pid == 0){
ChildProcess(); /* Do Child Process */
}else{
ParentProcess(); /* Do Parent Process */
}
return 0;
}다음과 같이 fork()함수는 fork에 실패하면 -1, fork에 성공 시 자식 프로세스(fork에 의해 만들어진 프로세스)에겐 0, 부모 프로세스(fork를 호출한 프로세스)는 자식 프로세스의 PID(Process ID, 프로세스 번호)를 리턴받습니다. fork에 성공하면 부모 프로세스와 똑같은 메모리를 복사해서 자식 프로세스를 만듭니다. 즉, 메모리에 있는 전역/지역 변수까지 모두 복사합니다. 코드를 이용해서 예시를 들어 보겠습니다.
int main(void){
pid_t pid;
pid = fork();
string localVar = "Yes, I am!";
if(pid == -1){
perror("fork failed!");
}else if(pid == 0){
cout<<"Child Process : Local Var, Global Var, are you there?"<<endl;
cout<<" LocalVar : "<<localVar<<", and I'm on addr "<<&localVar<<endl;
cout<<" GlobalVar : "<<globalVar<<", and I'm on addr "<<&globalVar<<endl;
}else{
cout<<"Parent Process : Local Var, Global Var, are you there?"<<endl;
cout<<" LocalVar : "<<localVar<<", and I'm on addr "<<&localVar<<endl;
cout<<" GlobalVar : "<<globalVar<<", and I'm on addr "<<&globalVar<<endl;
cout<<" Child PID : "<<pid<<endl;
}
return 0;
}위 코드는 fork() 부모 프로세스와 자식 프로세스가 이전에 선언된 지역 변수와 전역 변수에 접근하는것을 보여주는 코드입니다. 실행 결과를 볼까요.
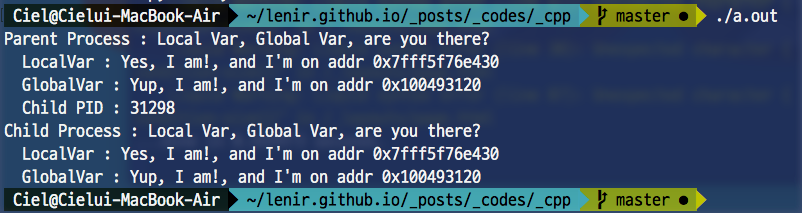 위 그림과 같이 두 프로세스 모두 접근이 가능한 것을 볼 수 있습니다. 더불어 두 변수의 논리 주소 또한 같은 것을 볼 수 있습니다. 이는 fork()가 메모리 전체를 복사하기 때문입니다.
위 그림처럼 말입니다. 지역변수는 아마 힙에 들어있을건데, 그걸 그대로 복사하니 같은 위치(같은 물리 주소 X, 같은 논리 주소 O)에 있는 겁니다.
위 그림과 같이 두 프로세스 모두 접근이 가능한 것을 볼 수 있습니다. 더불어 두 변수의 논리 주소 또한 같은 것을 볼 수 있습니다. 이는 fork()가 메모리 전체를 복사하기 때문입니다.
위 그림처럼 말입니다. 지역변수는 아마 힙에 들어있을건데, 그걸 그대로 복사하니 같은 위치(같은 물리 주소 X, 같은 논리 주소 O)에 있는 겁니다.
Thread
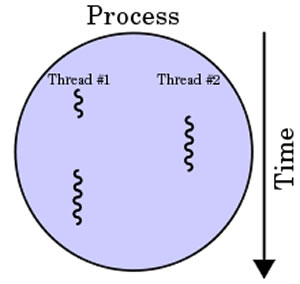 쓰레드란 영어로 실을 의미하죠. 실처럼 프로세스 내부에서 돌아가는 흐름을 말합니다. 프로세스는 최소한 하나의 쓰레드를 가지고 있습니다. 이를 한번에 여러개를 돌리는 것을 Multi-Threading이라고 하죠. 위 그림에서 프로세스가 두개의 스레드를 실행하는 것을 볼 수 있습니다. 조금 더 자세한 이해를 위해선 프로세스와의 비교가 필요할 겁니다. 바로 아래에서 자세히 살펴봅시다.
쓰레드란 영어로 실을 의미하죠. 실처럼 프로세스 내부에서 돌아가는 흐름을 말합니다. 프로세스는 최소한 하나의 쓰레드를 가지고 있습니다. 이를 한번에 여러개를 돌리는 것을 Multi-Threading이라고 하죠. 위 그림에서 프로세스가 두개의 스레드를 실행하는 것을 볼 수 있습니다. 조금 더 자세한 이해를 위해선 프로세스와의 비교가 필요할 겁니다. 바로 아래에서 자세히 살펴봅시다.
Multi-Processing VS Multi-Threading
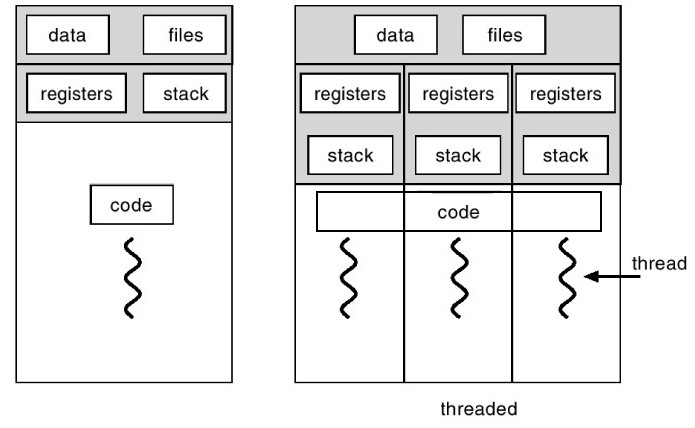 위 그림을 보시면 한번에 이해가 갈 겁니다. 멀티 프로세싱과 멀티 스레딩의 차이는 메모리의 차이에서 옵니다.
위 그림을 보시면 한번에 이해가 갈 겁니다. 멀티 프로세싱과 멀티 스레딩의 차이는 메모리의 차이에서 옵니다.
위에서 fork()는 프로세스의 메모리를 통째로 복사한다고 했는데, 멀티 프로세싱은 그와 같이 똑같은 메모리 구조가 여러개 한번에 돌아간다고 생각하시면 됩니다. 물론, 메모리를 모두 따로 갖고 있기 때문에 변수 공유따윈 되지 않고 프로세스 간 통신(IPC, Inter-Process Communication)을 이용해야겠지요.
그럼 쓰레드를 봅시다. 쓰레드는 코드, 데이터(힙)는 공유해서 가지고 있고, 스택은 따로 가지고 있습니다. 다시 말해서 변수 i를 A 스레드에서도 읽을 수 있고, B 스레드에서도 읽을 수 있는 겁니다. 그만큼 동시성이 높아지겠죠!
하지만 그런만큼 반작용도 있습니다. 대표적인 경우가 변수에 여러 스레드가 동시에 접근해서 의도치 않은 결과가 나오는 겁니다. 예를 들어보죠.